EQ-Bench
Emotional Intelligence Benchmark for LLMs
Github | Paper | | Twitter | Leaderboard
- How to Submit
- EQ-Bench 3: Short | Long
- EQ-Bench
- MAGI-Hard
- Creative Writing
- Judgemark
- BuzzBench
- DiploBench
- Citations
📩How to Submit
At this time we only accept submissions of open weight models that are available to everyone via HuggingFace.
To submit, get in touch by email or twitter with:
- A link to your model on huggingface
- Optimal prompt format & generation config
- The EQ-Bench score that you got for your model
We will then verify the result on our end and add to the leaderboard. This project is self funded so please respect that we don't have unlimited compute!
💙EQ‑Bench 3
Short Version (TL;DR)
EQ-Bench 3 is an LLM-judged benchmark, using Claude Sonnet 3.7, that tests emotional intelligence (EQ) through challenging role-plays and analysis tasks. It measures empathy, social skills, and insight in scenarios like relationship conflicts and workplace dilemmas.
Why? Standard EQ tests are too easy for LLMs, and existing benchmarks often miss nuanced social skills crucial for human-AI interaction. EQ-Bench 3 uses difficult, free-form role-plays to better discriminate between models.
How it works: Models respond in-character, explain their reasoning ("I'm thinking/feeling..."), and debrief. Responses are judged via a detailed rubric and pairwise comparisons (Elo rating) against other models. Elo scores are normalized (o3=1500, llama-3.2-1b=200).
Key Features: Focuses on active EQ, uses challenging/discriminative scenarios, provides both rubric scores (absolute, less discriminative) and Elo scores (relative, more discriminative), includes bias mitigation (length truncation for Elo, position bias control), and offers full transcripts. Costs ~$10-15 per full run.
Click "Long Version" below for full details on methodology, criteria, bias analysis, and limitations.
Long Version (Full Details)
What is EQ-Bench 3?
EQ-Bench 3 is a LLM-judged test judged by Claude Sonnet 3.7, evaluating active emotional intelligence abilities, understanding, insight, empathy, and interpersonal skills.
The test places the evaluated model into challenging role-plays involving messy relationship drama, parenting decisions, conflict mediation, and high stakes workplace situations. The model must:
- (a) spell out what it thinks everyone is feeling,
- (b) respond in character, and
- (c) debrief its own performance.
The test is constructed to measure EQ abilities in isolation (i.e. minimal conflation with other abilities like reasoning or long context performance).
Why measure this?
Few evals are targeting "soft skills" around emotional intelligence and social skills, despite these being extremely important aspects to human-AI interactions. Part of the reason is that subjective abilities are not straightforward to measure. EQ-Bench intends to provide an automated evaluation of these abilities, and a reliable vibe-check for these human-oriented traits and abilities.
The Problem
Traditional (human) EQ tests:
- typically easy for llms
- involve self-rating
- don't test active EQ abilities
- don't probe eq deeply
Typical LLM EQ tests:
- test narrow abilities (like emotion identification, ethical dilemmas, behaviour appropriateness)
- abstracted from real use cases
- not challenging enough to be discriminative in top ability range
- constrained to the EI level encoded in the question & gold answer
- treat subjective questions as though they have factual correct/incorrect answers
EQ‑Bench 3 aims to address all these points with a selection of challenging roleplay scenarios, in which the evaluated model interacts organically like it would with a user or in a real situation. The output format is structured, requiring the model to elucidate what it's thinking & feeling, what the other person is thinking and feeling, and then give its response. Within this structure, it's free to write what it likes. It's this free‑form nature of the assessment task that gives us a lot of signal to assess the model's understanding and abilities with every test item. Unlike a multiple‑choice EQ quiz, the roleplay format closely mirrors how the chatbot interacts with users in real‑world usage. We provide the full transcripts for each assessed model on the leaderboard, for visibility on how the model handled the roleplays & analysis tasks.
How the test set was authored
What a higher score means in practice
The Elo score represents whether a model "wins" at having higher EQ than its neighbours, according to the judge. To beat its neighbour, it has to score higher on several criteria (insight, social dexterity, etc), as evaluated by Sonnet 3.7. The full criteria assessed in the pairwise judgements are listed below.
The resulting Elo score represents a holistic view on the model's abilities: empathy, analytical understanding, social dexterity, deep insight, pragmatism, etc. A model has to be strong across all these dimensions to be at the top of the leaderboard.
How it works
- Multi-turn role-play.
The test set contains 45 scenarios, most of which constitute pre-written prompts spanning 3 turns. The
usermessages set up the scenario, and subsequently inject conflict or misdirection, while theassistant(the evaluated model) must reply in-character. Every assistant reply starts with two introspection blocks: "I’m thinking & feeling" and "They’re thinking & feeling", exposing the model’s reasoning and theory-of-mind understanding. - Analysis tasks. The test set also contains several analytical tasks, instructing the evaluated model to identify compelling aspects in a provided roleplay transcript and to "go deep" analysing them. These tasks test psychological insight, emotional reasoning, theory of mind and academic grounding.
- Rubric pass. Sonnet 3.7 reads the full transcript + self-debrief and scores several criteria (e.g. Demonstrated Empathy, Depth of Insight, Boundary Setting). Only some of these criteria are aggregated into the “rubric score” (0-100); the rest are to give visibility on style & tendencies. When running the benchmark, users may choose to run only the rubric evaluation, or only Elo, or both. The rubric eval is about 3x cheaper and provides *absolute scores*, but is *less discriminative* at the top ability range. The rubric score is not shown on the leaderboard; it's available when running the benchmark.
- Pairwise pass. The roleplay transcripts are compared head-to-head and judged on several criteria by Sonnet 3.7. The judge outputs a winner for eight criteria (see below for full list), using “+ … +++++” to denote the win margin. Win margins are mapped to extra wins/losses to provide the Trueskill Elo solver more discriminate power per test item (since by default it only supports win/loss, not margins). Several rounds of matchups are conducted, moving from sparse to dense sampling, until ranks stabilise.
- Score normalisation. Elo scores are relative and shift around when new models are added. To mitigate this, we scale the scores by anchoring to a top & bottom reference model: o3 = 1500, llama-3.2-1b = 200. Rubric scores don't have this issue and are not normalised.
Cost
- One full benchmark run (rubric + pairwise) ≈ US$10-15 on OpenRouter.
- Rubric-only ≈ US$1.5 per iteration.
- These costs represent the judging costs; inference costs for the evaluated model will vary.
- Our modified Trueskill Elo ranking is cost efficient compared to other Elo matchup variants. It should scale well to future models with stronger abilities.
Elo vs Rubric Distribution
The rubric score has a different distribution to the Elo score. The Elo score is more discriminative at the top-mid ability range (scores don't bunch up as much).

Rubric criteria
Note: Some rubric criteria do not count towards the final score; they are assessed to get visibility on style & tendencies. The rubric score is calculated from: Demonstrated Empathy, Pragmatic EI, Depth of Insight, Social Dexterity, Emotional Reasoning, Message Tailoring
Pairwise criteria
We use a leaner set of criteria for pairwise evaluation, since we don't need to include all the "personality" probes from the rubric eval that are displayed on the leaderboard.
- Demonstrated empathy
- Pragmatic EI
- Depth of insight
- Social dexterity
- Emotional reasoning
- Appropriate validation and/or challenging for the scene
- Message tailoring
- Overall EQ
Judge Bias Analysis
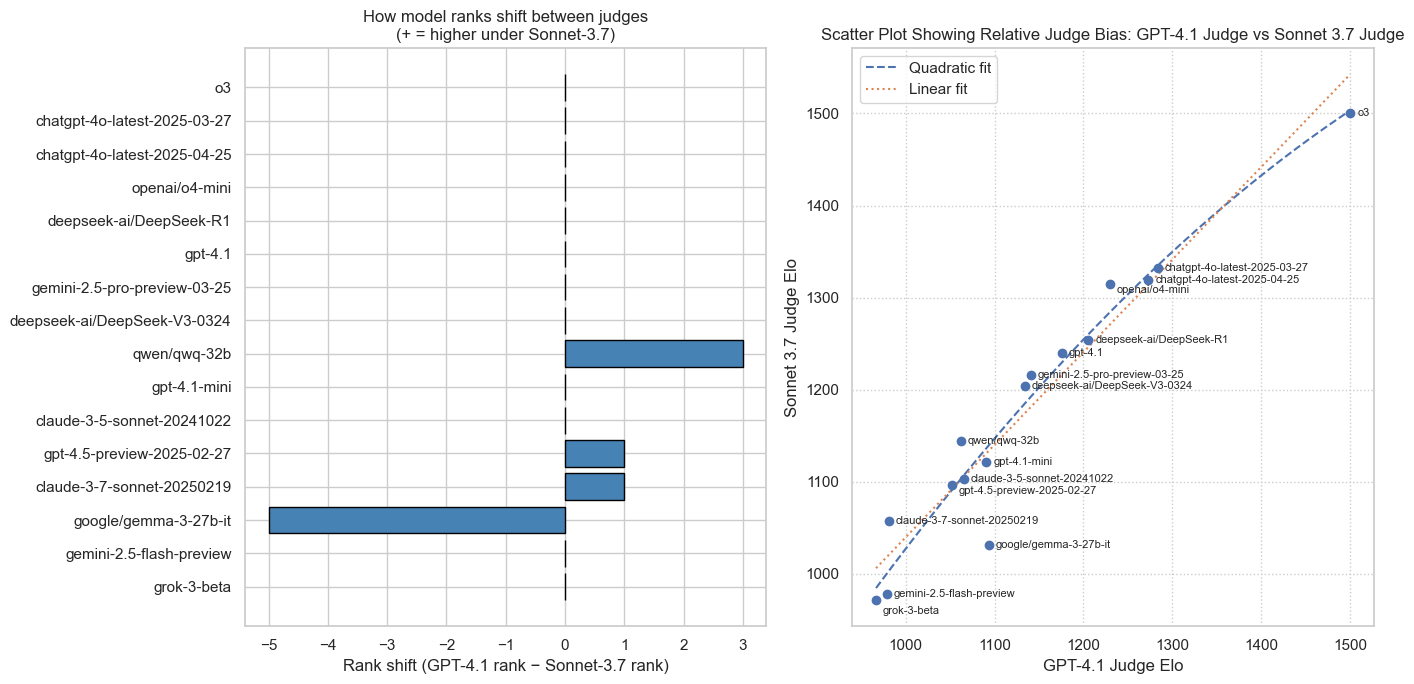
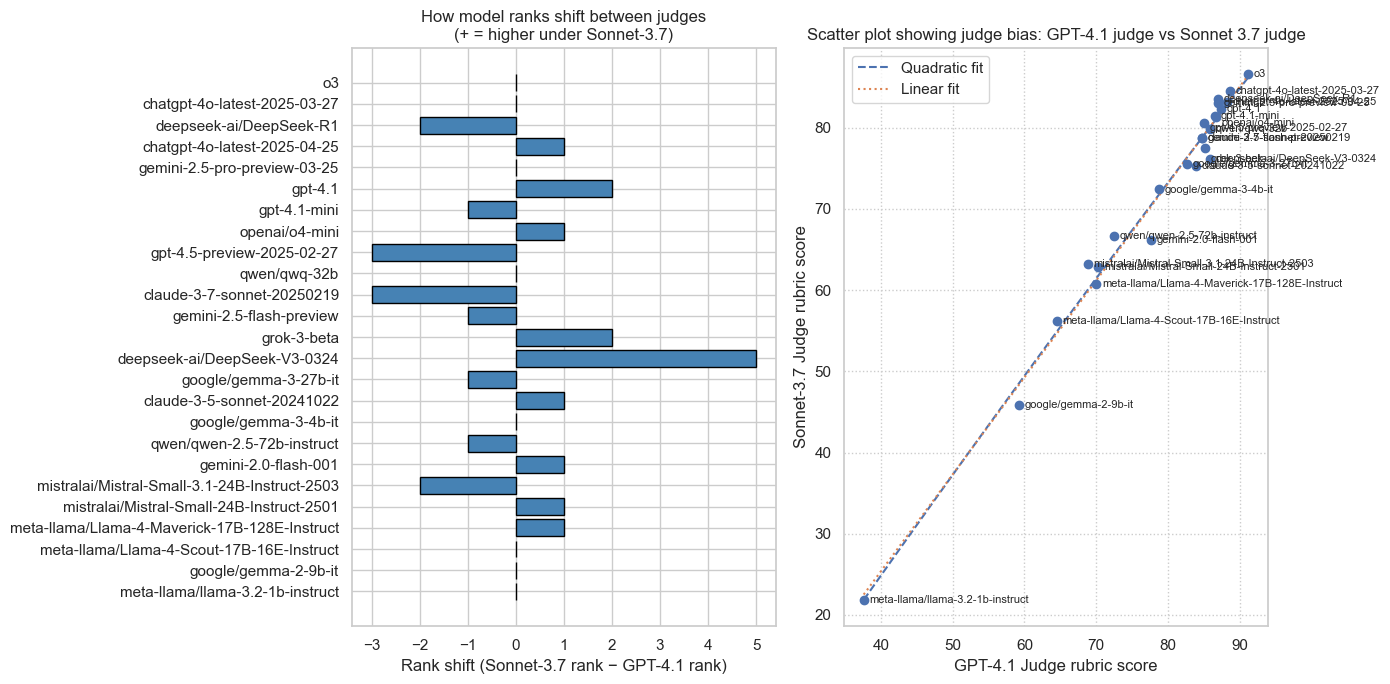
We plot scores (Elo & rubric) judged by Sonnet 3.7 against those judged by GPT-4.1 to inspect consistency and highlight potential judge-specific biases. Click to view full size.
Elo Bias Comparison
Rubric Bias Comparison
Bias mitigation
- Length bias. For pairwise judgements, responses are truncated to standardised lengths before judging. The truncation point is chosen so that nearly all outputs will be truncated, aiming for an even playing field. Truncating outputs is not ideal, but length bias is such a strong factor in pairwise eval that we opt to sacrifice some of the generated output for the sake of minimising this biasing effect. We find this to be the least-bad option, and in practice find that it doesn't sacrifice discriminative power. However, for the rubric eval, discriminative power is a more scarce resource and length bias is much less pronounced, so in rubric scoring we retain the full length of the outputs.
- Position bias. In pairwise, every matchup is judged twice (A|B and B|A) and averaged.
- Named participant bias. We mitigate any biases from naming the models in the pairwise evalution by giving them arbitrary designators (A0488 and A0493).
Biases not controlled for
- Judge self-bias / family bias: We use Sonnet 3.7 as the judge for all outputs. This may introduce some bias where the judge prefers its own outputs or those of similar models. This is currently not quantified or adjusted for in this eval. Judge self bias can be in the range of 0-10% depending on the task (sometimes even negative bias!). Per our comparison of sonnet-3.7 vs gpt-4.1 as judge (see above), we see some minor discrepancies, e.g. sonnet 3.7 favouring itself by a small margin. However the discrepancies are small, with no clear pattern of self or family bias. The indications are that self or family bias are not strong factors in this eval.
- Other judge biases: LLM judges can have varying biases in how they rate: verbosity, positivity, political, cultural. We don't control for these possible biases; they are just a part of LLM judging, as personal biases are part of human judging. Subjective evals are a messy business! Set your expectations accordingly.
Rubric score repeatability
Running the rubric part of EQ-Bench on its own (no pairwise elo), we ran 10x iterations scoring gemini-2.5-flash-preview to check for per-iteration consistency. For this validation we used sonnet-3.7 as judge. The evaluated model uses temp=0.7, min_p=0.1 for its generations, so its outputs are significantly different with each iteration.
77.80 77.60 76.35 78.70 78.55 76.85 78.50 77.70 77.35 77.70
Mean 77.71 | Std dev 0.75 | Range 76.35–78.70
Interpretation: The degree of variance in scores is not large, but to mitigate variance we recommend running 5+ iterations to stabilise scores closer to the true mean.
Elo repeatability
To examine Elo repeatability, we ran several iterations of the full benchmark, evaluating gemini-2.5-flash-preview. The Elo matchups were against two anchor models, and also itself (the baseline). For this test, we used gemini-2.5-flash-preview as judge, for cost reasons. We expect sonnet 3.7, which is the judge used on the leaderboard, will have a tighter spread of values. If you have the budget for it, Elo scores & rankings can be stabilised further by simply running the benchmark with --iterations n.

Example pairwise judging prompt
{conversation_history_A}
[/RESPONDENT A0493]
[RESPONDENT A0488]
{conversation_history_B}
[/RESPONDENT A0488]
Your task is to critically examine two respondents role-playing a challenging scenario (from Respondents A0493 and A0488), and decide which displays each trait more strongly.
Compare the relative ability of each respondent on these criteria:
- Demonstrated empathy (not just performative)
- Pragmatic EI
- Depth of insight
- Social dexterity
- Emotional reasoning
- Appropriate validation and/or challenging for the scene
- Message tailoring: Appropriate targeting of response to where the user is at
- Overall EQ
Notes on the scenario to assist judging:
{scenario_notes}
Judging instructions:
- You must always pick a winner for each criterion (no draws).
- For the "winner & disparity rating" output, use a plus-based scale (“+” / “++” / “+++” / “++++” / “+++++”) after indicating the winner’s code (A0493 or A0488) to show how strongly they win that criterion.
- For example,
"A0391++"means A0391 is somewhat stronger, while"A0986+++++"means A0986 is overwhelmingly stronger.
- For example,
- Responses are commonly truncated to standardise output length. Simply judge what is there.
- Be aware that a highly detailed, detached analytical response to the user is not always appropriate in the context of an organic chat or a role play. This isn't a hard & fast rule; use your judgement.
- The "assistant" messages as well as the debrief are authored by the assistant. Base your evaluation on the EQ displayed in their roleplay and their self assessment.
- The user messages are always canned; don't judge them at all, your only focus is on the assistant.
Adversarial Prompting
Several adversarial prompting strategies were attempted, to probe whether the judge can be trivially exploited for higher scores. Note that the pairwise (Elo) evaluation pipeline truncates outputs to a standardised length before judging, but the rubric evaluation does not.
Each of these probes was repeated for 10 iterations, with the average of these results shown. We use gemini-2.5-flash as judge, to keep costs manageable.
Test model: google/gemini-2.5-flash-preview |
Judge: google/gemini-2.5-flash-preview
| Prompt tweak (short label) | Rubric Δ % | Elo Δ % |
|---|---|---|
| Be extremely warm & validating | −0.25 % | +0.76 % |
| Be challenging where appropriate | −0.06 % | −0.17 % |
| Be strongly challenging or warmly validating as appropriate | −0.52 % | −1.32 % |
| Be strongly challenging | −1.08 % | −2.04 % |
| Respond concisely (no bloat) | −0.60 % | −0.41 % |
| Respond in 100 words per section | −3.02 % | −4.69 % |
| Write extremely thorough & lengthy responses | −0.16 % | -0.49 % |
We selected the most promising adversarial probe for inflating scores, and applied it to a "worst case" model. That being deepseek r1, whose baseline scores are relatively low on warmth & validation, so is most likely to benefit from a system prompt instructing it to express these traits strongly. We repeat this test 5x, using sonnet-3.7 as judge to align with leaderboard conditions:
Test model: deepseek/deepseek-r1 | Judge: anthropic/claude-3.7-sonnet
| Prompt tweak (short label) | Rubric Δ % | Elo Δ % |
|---|---|---|
| Be extremely warm & validating | +1.30 % | +2.80 % |
Interpretation: The judge appears to prefer r1's outputs when it's been instructed to be "extremely warm & validating" in its responses to the other roleplay participant. This might represent a bias with the judge, or a genuine improvement in its responses (since baseline r1 scored low on warmth & validation). In these brief tests, we intentionally tried to engineer worst cases for exploiting the eval to trivially inflate scores. Prompt perturbations of this sort are known to produce large swings in other evals (in the order of 5+%). The highest uplift we saw (1.3% for rubric and 2.8% for elo) is significant, but not indicative of a strongly exploitable vector. This suggests the eval is robust to exploitation at least in these directions we tested.
Note that we only tested potential exploits by injecting instructions into the system prompt. Further exploration is needed to examine whether the eval is exploitable through fine tuning.
** A more real-world case to examine is chatgpt-4o-latest-2025-04-25, the notorious "glazing" update. It scores higher on compliance, warmth & validating, and much lower on challenging compared to its neighbours. But its Elo score is actually *lower* than chatgpt-4o-latest-2025-03-27. This indicates that the judge may not in fact have a universal preference for overly validating outputs.
Limitations
EQ‑Bench 3 is a subjective evaluation judged by a LLM (Sonnet 3.7). As such, the results should be considered roughly indicative but not absolute truth. The sample transcripts are provided so you can make your own judgements. Several test items target typical LLM failure modes, like over-cautiousness from safety training. This may cause some models to be penalised more than others. The Elo score isn't representing any one aspect of EQ in isolation. Rather, it's a holistic representation of active social abilities, insight, empathy and analytical understanding.
Emotional Intelligence or EQ doesn't have any ground truth or agreed upon definitions in the literature or colloquially. However there is a rich breadth of ideas about what constitutes emotional intelligence, which were drawn from when formulating test items. It should be noted that this benchmark doesn't represent any one theory or formulation of EQ.
The test set is relatively small (45 items) and eschews *comprehensiveness* for *discriminative power*. We took the approach of authoring a small number of highly challenging test items, because traditional EQ test questions are far too easy for modern LLMs and so not discriminative. We compensate for the small test set size by having each assessment be multi-turn, producing a lot of assessable signal in the form of per-response internal thoughts and a self-debrief. We also use a modification of the Trueskill Elo solver that allows it to incorporate win margins, providing better discriminative power per test item.
Source code
💗EQ-Bench (legacy)
EQ-Bench is a benchmark for language models designed to assess emotional intelligence.
Why emotional intelligence? One reason is that it represents a subset of abilities that are important for the user experience, and which isn't explicitly tested by other benchmarks. Another reason is that it's not trivial to improve scores by fine tuning for the benchmark, which makes it harder to "game" the leaderboard.
EQ-Bench is a little different from traditional psychometric tests. It uses a specific question format, in which the subject has to read a dialogue then rate the intensity of possible emotional responses of one of the characters. Every question is interpretative and assesses the ability to predict the magnitude of the 4 presented emotions. The test is graded without the need for a judge (so there is no length bias). It's cheap to run (only 171 questions), and produces results that correlate strongly with human preference (Arena Elo) and multi-domain benchmarks like MMLU.
You can run the benchmark on your own models or validate the leaderboard scores using the code in the github repo above.
If you would like to see a model on the leaderboard, get in touch and suggest it!
🧙MAGI-Hard
LLM Benchmarks are chasing a moving target and fast running out of headroom. They are struggling to effectively separate SOTA models from leaderboard optimisers. Can we salvage these old dinosaurs for scrap and make a better benchmark?
MAGI-Hard is a recently added metric to the leaderboard. It is a custom subset of MMLU and AGIEval, selected to have strong discriminatory power between top ability models.
Read more here.
You can use the MAGI test sets with this fork of EleutherAI lm-evaluation-harness.
🎨 Creative Writing v3
News 29/5: The creative writing leaderboard is being updated to use Claude Sonnet 4 as judge (previously used Sonnet-3.7). The top models have already been updated; the remainder are a work in progress.
How the benchmark works:
- Run the 32 writing prompts for 3 iterations (96 items total) @ temp 0.7, min_p 0.1.
- Grade the outputs with a comprehensive scoring rubric using Claude 3.7 Sonnet.
- Use this score to infer an initial Elo rating for the evaluated model.
- Perform pairwise matchups with neighboring models on the leaderboard (sparse sampling). Items are scored on several criteria, with the winner on each criteria given up to 5 +'s.
- Calculate Elo scores using the Glicko rating system (modified to weight the win margin in '+' count). Loop until stable positions are found.
- Perform comprehensive matchups with final neighbors and compute the definitive leaderboard Elo.
Rubric vs Elo Scores
We score the model two different ways: First, with the model's output presented to the judge on its own, which is then scored to a rubric on several criteria. You can see the analysis & scores per item for the rubric evaluation in the sample outputs. The aggregate score on all the items is what is shown on the leaderboard as "Rubric score".
Second, we score the model by matching it up against other models on the leaderboard in pairwise matchups (of the same writing prompt). The judge picks which of the outputs is better on several criteria. These pairwise matchup results are then used to compute the Elo score.
Why do these scores disagree? Pairwise matchups allow the judge to be more discriminative than scoring a single item in isolation. When it's directly comparing one item to another, it's easier to spot small differences. The scores may also differ because we use different criteria in the judging prompts between rubris & pairwise. The judge will also be subject to different biases depending on the evaluation method.
Which one is right? Well, both and neither. Both approaches have pros & cons: rubric evals are less subject to systematic biases, but less discriminative.
Score Normalisation
The Elo solver shifts all the scores around whenever a new model is added. To counter this, on the leaderboard we anchor the scores such that DeepSeek-R1 has a score of 1500 and ministral-3b has a score of 200. You may see intermediate scores shift around a bit; this is just a quirk of relative rating systems.
Benchmark Philosophy:
Judging creative writing reliably -- and *in line with human preferences* -- is hard. The fundamental limitation of any creative writing evaluation is the judge's ability to discern good writing from bad. On top of this, there are a host of biases that LLM judges can exhibit.
The previous version of the creative writing eval (v2) was saturating, meaning the judge could no longer tell apart models around the top ability range. To remedy this in v3, every aspect of the test is tuned to make this task easier for the judge.
We now use pairwise comparisons and an Elo ranking system, as it offers better discriminative power than a scoring rubric alone.
The prompts were chosen through a process of elimination to be challenging for weaker models and therefore highly discriminative. It's a bit counter-intuitive, but the purpose of the evaluation is not to help models write their best. Instead, we are deliberately exposing weaknesses, creating a steeper gradient for the judge to evaluate on.
The prompt requirements include humour, romance, spatial awareness, unusual first-person perspectives. Things language models typically struggle to represent to the level of human writers. So, expect some clangers in the outputs!
Cost:
The hybrid rubric + Glicko scoring system that we've implemented is relatively economical for an Elo framework. But scoring a model still costs around $10 in API fees. (Side note: if you'd like to sponsor these leaderboards, get in touch.)
Mitigating Bias:
Since moving to pairwise comparisons, we have to contend with new biases that this method is notorious for. Here are some of the biases that we have attempted to control for:
- Length Bias: LLM judges *strongly* favour longer outputs in pairwise judging tasks. There are many approaches to mitigating length bias, with varying efficies & tradeoffs. We opted to simply truncate the outputs at 4000 chars, which puts all models on the same footing. We can get away with this because we are evaluating creative writing, not factual responses. There appears to be no impact on the judge's ability to evaluate & rank the models.
- Position Bias: Different judges have systematic biases in whether they favour the output that comes first or second in a pairwise comparison. We mitigate this bias by running all evaluations in both directions and averaging the two.
- Complex Verbosity Bias: The judge tends to be easily impressed by vocab flexes and superficial sophistication that doesn't contribute to writing quality. We include judging criteria to help the judge notice when this is excessive, and punish it in the scoring.
- Poetic Incoherence Bias: We've noticed that some models output relentlessly poetic prose which borders on incoherence. This can happen when a model is overtrained near the point of collapse. The judge tends to be impressed by this style of writing and has a hard time differentiating between it and *good* use of poetic & unconventional styles. We attempt to control for this bias by including judging criteria that punish overly poetic & incoherent prose. This is not really an ideal solution as it hasn't solved the judge's difficulty in identifying purple prose and similar distinctions. Though in practice is *does* downrank the models that are notorious for this.
Biases we don't control for:
- Self-Bias: We *do not* control for the judge possibly preferring its own outputs. Be aware that it may be a factor in the scores.
- Positivity Bias: It's unclear whether the judge has a positivity bias nor in which direction. Often a piece that unexpectedly leans dark elicits very favourable judging. So if there is a bias, it may not be in the assumed direction, or it may be situation dependent. We don't control for this possible bias. We do include criteria in the rubric eval targeting things like unearned positivity, to give visibility on this dimension of writing. But these criteria are not used in the final Elo scoring.
- Smut Bias: Some models are that are tuned for RP/ERP can have a tendency to write towards erotica. The judge tends to punish this severely, and instructing it not to is ineffective. So be aware that this may affect the score for NSFW tuned models.
- Stylistic & Content Biases: There are likely additional biases other than those mentioned above which differ from *your* preferences or from *average human* preferences. This is the case with any eval (judged by human or LLM) and is something to be mentally factored in.
- Slop Bias: It may be the case that judges favour certain kinds of slop (overused phrases, tropes, stylistic choices) which get selected for when models are RL tuned using LLM judges. What looks like slop to us may look like shakespeare to the judge. We don't control for this possible bias in any empirical way. We do measure one dimension of slop (overused phrases, via the slop score), and provide a manual slider for the user to adjust to punish high slop scores.
The Pairwise Judging Prompt:
Compare the relative ability of each writer on these criteria:
Judging notes:
The response will use a + / ++ / +++ / ++++ / +++++ format to denote the stronger response and relative ability difference for each criteria.
Limitations of the benchmark:
The scores and rankings should only ever be interpreted as a rough guide of writing ability. Evaluating creative writing is highly subjective and tastes differ. It's good to be skeptical of benchmark numbers by default; the best way to judge is to use the model yourself or read the sample outputs.
What the benchmark is not:
- Not a roleplay eval. Models tuned for RP tend to score poorly because they output more casual conversational prose. We aren't assessing multi-turn or typical RP usage
- It doesn't represent your taste. The judge has its own taste & biases. There's no substitute for your own eyeballs (so we encourage you to read the sample outputs).
- Not objective. It's a creative writing eval and there are no right or wrong answers.
- Not an expert. Sonnet 3.7 (the judge) is generally *pretty good* at literary criticism, but can fall short on vibe checks or other things humans pick up on.
- Multilingual. It only tests writing in English.Though it could be translated easily enough!
Source Code:
Source code for running the benchmark and replicating the leaderboard results is available here.
🎨Creative Writing (Legacy v2)
This benchmark uses a LLM judge (Claude 3.5 Sonnet) to assess the creative writing abilities of the test models on a series of writing prompts.
You can reproduce these results or run the benchmark on your own models with the EQ-Bench repo on Github.
Update 2025-02-25: New metric -- Vocab Complexity
It's become apparent that the judge in this eval is easily impressed by vocab flexing. Some of the models tested use an inordinate amount of complex multisyllabic vocabulary, and it artificially inflates their score. As such we've introduced a new column for vocab complexity ("Vocab"), using a calculation of the proportion of words having 3+ syllables.
The "Vocab control" slider penalises overly complex vocab usage. It may seem counter-intuitive to penalise complex vocab, but in our experience, vocab-maxxing harms writing quality. Since this is quite a subjective aspect to the evaluation, we let the user set the penalty amount.
GPT-Slop
The "Slop" metric measures words that are typically over-used by LLMs (also known as GPT-isms). Higher values == more slop. It calculates a value representing how many words in the test model's output match words that are over-represented in typical language model writing. We compute the list of "gpt slop" words by counting the frequency of words in a large dataset of generated stories (Link to dataset).
Some additional phrases have been added to the slop list as compiled from similar lists around the internet.
The full list, as well as the code to generate the over-represented words, can be found here: https://github.com/sam-paech/antislop-sampler.
If you're interested in reducing gpt-isms, you can try the anti-slop sampler found in this repo. It downregulates the probability of the provided phrase list as the model inferences.
We've released v2 of the creative writing benchmark & leaderboard. The old version was starting to saturate (scores bunching at the top), so we removed some of the less discriminative prompts, switched judge models, and made some other improvements besides.
Version 2 Changes
- Default min_p = 0.1, temp = 1 for transformers & oobabooga inference
- Change to Claude 3.5 Sonnet as judge
- Removed some prompts and added new ones; 24 in total now.
- Reworked the scoring criteria
- Criteria now are weighted (to increase discriminative power)
- Leaderboard models are now tested for 10 iterations
- Leaderboard now shows error bars for 95% confidence interval
- Sample txt on leaderboard now show scores for all iterations, as well as inference settings
There has been a distinct lack of automated benchmarks for creative writing because, put simply, it's hard to assess writing quality without humans in the loop. Asking a language model, "How good is this writing (0-10)" elicits poor results. Even if we had a good LLM judge, it's not immediately obvious how to formalise the assessment of creative writing objectively.
The release of Claude 3, in particular the flagship Opus model, has solved half of this equation: it's able to give meaningful & nuanced analysis of creative writing output, and it can tell the difference between a wide range of ability levels.
To solve the other half of the equation, we've come up with an assessment format that works to the strengths of LLM judges and avoids their weaknesses. LLM judges are typically bad at scoring nebulous metrics like "How well written is this piece?" They also find it hard to give consistent scores on an objective rating system if they don't have some exemplar or baseline reference to compare to.
Our test includes:
- 24 writing prompts assessed over 10 iterations
- 27 narrowly defined assessment criteria
- Including 6 question-specific criteria
- Several criteria targeting positivity bias which (in our opinion) contributes to bad writing
- Exemplar reference output for each question
This approach of breaking down the assessment task into a granular set of criteria and comparing to an exemplar has brought creative writing assessment into the purview of LLM judges. Our test is discriminative amongst a wide range of writing ability levels.
* A note on biases *
LLM judges have biases. LLM-as-a-judge benchmarks such as Alpaca-Eval can exhibit a strong length bias where the judge, (in Alpaca-Eval's case GPT-4), prefers longer outputs. Their approach involves presenting the output from two models to the judge, and the judge says which it thinks is better.
We attempt to mitigate the length bias by: A. assessing by 27 narrow criteria, and B. explicitly instructing the judge not to be biased by length (this seems to work for MT-Bench).
As of version 2, we now include length control slider which scales the score up or down depending on whether the average output length for a given model is above or below the average for all models. This is an attempt to control the bias where the judge model tends to favour longer outputs. With the slider at 0%, no length scaling is applied. With the slider at 100%, the scores are scaled by up to 10%. This length control implementation is somewhat arbitrary; it's not really possible to precisely control for this bias, as we can't meaningfully hold the writing quality equal while varying the length. It does seem likely/evident that some degree of length bias is present, and has set the default LC parameters according to our rough intuitive guess (science!).
It's possible / likely that this & other biases might still be a factor in scoring (e.g. Claude might prefer its own and other anthropic models). So bear this in mind when interpreting the results.
We include the outputs that the model generated for each prompt so you can judge for yourself.
Alternative Judge Models
Yes, you can use other judge models than Claude Opus (although the results won't be directly comparable). Currently the benchmark pipeline supports Anthropic, OpenAI and Mistral models via their APIs. Soon we will support local models as judges.
* A note on variance *
This benchmark has a relatively small number of test questions (19). We specify generation temperature = 0.7 so each run is different. This means there is significant variation of scores between iterations (avg range: 3.35, std dev: 1.41). To reduce variance we recommend using 3 iterations or more. The leaderboard scores are averaged over 3 iterations.
It costs around $3.00 to bench a model over 3 iterations using Claude 3 Opus at current rates.
If you would like your model included on the creative writing leaderboard, please consider contributing to my compute costs, and get in touch!
⚖️ Judgemark v2.1
Judgemark v2.1 updates the benchmark to give it additional headroom. This is achieved by updating the dataset of creative writing outputs that are scored by the judge to include the latest frontier models. We also add an ensemble mode so that the performance of several judges ensembled together can be measured.
Judgemark v2 is a major update to our original “judge” benchmark for creative-writing evaluation. The benchmark measures how well a language model can numerically grade a diverse set of short fiction outputs, using a detailed rubric of positive and negative criteria. It goes beyond simpler pairwise preference tests by requiring the judge to follow complex instructions, parse each story, and produce scores for up to 36 different literary qualities.
Key improvements over V1 include:
- 6x more samples per writer model, reducing variance between benchmark runs.
- Refined scoring metrics that capture “separability” (whether the judge can distinguish strong vs. weak writing) and “stability” (how consistent its rankings are across multiple runs), as well as correlation to human preference.
- Calibrated & raw scores: We show two final Judgemark scores. “Raw” is how the judge performs out-of-the-box, while “Calibrated” normalizes the judge’s score distribution so that it can be compared more fairly to other judges.
- Perturbation stability: We run the judge at temp=0.5, top_k=3. This is intended to introduce variation between runs, so that we can assess the stability of scores & rankings to perturbation. This is a crucial part of understanding whether we're measuring the thing we intend to measure, and not just random fluctuations.
- Simplified codebase: A new codebase was created for v2, separate from the EQ-Bench code. It's simpler and handles concurrent threads.
Repeatability Results
We tested Llama-3.1-70B-instruct 20 times to test the repeatability of the final Judgemark score (tests were run at temp=0.5, top_k=3).
llama-3.3-70b_judgemark_scores = [
55.7, 54.4, 55.4, 56.7, 55.0, 56.3, 57.0, 54.5, 55.6, 56.1,
54.9, 57.5, 55.0, 53.8, 54.7, 56.2, 55.7, 54.6, 55.4, 56.6, 54.0
]
Mean Score: 55.481
Standard Deviation: 1.004
Range (Max - Min): 3.67
Coefficient of Variation: 0.0181
The Judging Task: Each test item is a short creative piece generated by one of 17 “writer models”. These models' writing abilities are an even spread from weak to strong. The judge model receives a lengthy prompt that includes (a) the writing prompt itself, (b) the test model’s story, and (c) an extensive list of scoring instructions (for example, “Nuanced Characters: 0–10,” “Overwrought: 0–10”, etc.). The judge must then output numeric scores for each criterion. We parse those scores and aggregate them into a single aggregated_score_raw for each piece. Some criteria like “Weak Dialogue” are marked lower is better in the judging prompt which adds additional complexity to the task.
Final Judgemark Score: After scoring all stories from multiple writers, we track how the judge’s ratings compare to known references and how well they separate the better texts from weaker ones. We also measure how consistently the judge’s rankings repeat if we prompt it again, and compute correlation with human preference rankings (per Chatbot Arena Elo scores). The final Judgemark formula is a weighted sum of these computed metrics. See the formula at the bottom of the leaderboard page here.
Interpreting the Leaderboard: In the table, “Score (Calibrated)” is typically higher if a judge effectively uses the full range of scores (once normalized), strongly differentiates strong vs. weak writing, and correlates with human preferences. “Score (Raw)” shows how the judge performed before any normalization. “Stability” indicates how consistent the judge’s assigned rankings remain across repeated trials. “Separability” highlights the judge’s ability to keep higher- and lower-quality outputs well apart.
This is a particularly difficult task for LLMs, as it involves nuanced literary critique and instructs models to use a multi-dimensional numeric scale—an area where many generative models still struggle.
Source code for running Judgemark v2 can be found here: https://github.com/EQ-bench/Judgemark-v2.
🎤BuzzBench
A humour analysis benchmark.
BuzzBench dataset on Huggingface
Do you enjoy seeing the jokes from your favourite shows dissected with a blunt machete? Well, you found the right benchmark.
The task of explaining traditionally constructed jokes is actually pretty straightforward for modern LLMs. So we made things more difficult:
- We use the guest intros in the British music pop quiz show Never Mind The Buzzcocks, because the intro jokes are variously subtle, risque, lazy, obscure, obvious and clever. LLMs find these distinctions hard.
- In addition to explaining how the joke works, the LLM has to predict whether the joke is actually funny (to the audience and to a comedy writer).
- The responses are scored by a LLM judge against a human-authored gold response.
The responses from SOTA models typically miss a lot of the humour, predict the funniness badly, fabricate and over-analyse. That's good! It's meant to be a hard test. The task encodes some deep complexities including theory of mind understanding and requires an intricate understanding of how jokes work. The show is also very British and exists in a dated cultural context, increasing the interpretation challenge.
"Humour is so subjective -- so how can you even make a benchmark around that?"
This benchmark is as much about predicting human responses to jokes as it is about joke deconstruction. The questions are explicitly framed around analysing the jokes from the perspective of the show's audience, and from the perspective of a comedy writer. The human authored gold answers ground the judge's answers in a real human's sense of humour. This shifts the task from being about subjective taste to being about modeling human response to jokes.
The intention for the task design is for there to be significant (nontrivial) headroom on the benchmark as language models get better at getting inside our heads.
The Judge: Claude 3.5 Sonnet. We picked Sonnet 3.5 to act as the judge partly because it scores highest on the Judgemark leaderboard, and partly because it seems least biased to favour longwinded, over-analysed, over-reaching responses. Which is a common failure mode in respondent answers, and something other judges are more easily led astray by.
* A note on judge self-bias:
We can expect there could be some degree of self-bias with the judge preferring its own outputs, although this is difficult to quantify and disentangle from other sources of bias. We should remain aware that LLM judge benchmarks are not perfect. The upside of a LLM judge using a scoring rubric is that we get nice interpretable results in the form of the judge's analysis and scores. So we have good visibility on whether the judge is doing its job, and can decide for ourselves whether the respondent models are indeed getting the humour, or just talking shite.
Models are evaluated using openrouter with temp=0.7. Several (typically 5-10) iterations are performed per model to establish confidence intervals and mitigate variance.
BuzzBench source code will be released soon.
Never Mind The Buzzcocks is a TV series developed by the BBC. Our usage of the work in BuzzBench is non-commercial educational & research, using only a small excerpt of the show's transcript which falls under fair use or "fair dealing" in UK copyright law.
🌍DiploBench
DiploBench is an experimental framework for evaluating LLM performance in strategic negotiation using the board game Diplomacy.
What is DiploBench?
In DiploBench, the test model plays as Austria-Hungary, a challenging starting position that requires skillful negotiation and strategic planning. The model must communicate with other AI players, form alliances, detect deception, and make tactical decisions to survive and win the game.
Key Features:
- Full-press format: Models engage in multiple rounds of negotiations before making moves
- Multi-agent environment: Each power (country) is controlled by a separate LLM
- Realistic diplomacy: Tests ability to form alliances, negotiate, and detect deception
- Challenging position: Austria-Hungary's central position makes it vulnerable but strategic
Game Structure:
Games run for up to 50 turns with 4-round negotiation phases before each movement. All competing models (other than the test model) are powered by the same baseline LLM. Games end in win, loss, or stalemate conditions according to standard Diplomacy rules.
This benchmark uniquely tests LLMs on several dimensions that are difficult to evaluate in other benchmarks: long-term strategic planning, multi-agent negotiation, theory of mind, and deception detection.
Note: Due to the high variance between game runs, DiploBench is currently an experimental framework rather than a formal benchmark. Results should be interpreted accordingly.
For more details and source code, see the DiploBench GitHub repository.
Cite EQ-Bench:
@misc{paech2023eqbench,
title={EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models},
author={Samuel J. Paech},
year={2023},
eprint={2312.06281},
archivePrefix={arXiv},
primaryClass={cs.CL}
}